
Canvas launched the initial cut of its FHIR API at the end of March in 2021. At that time we supported just enough endpoints to support a simple patient registration and appointment scheduling flow. Almost exactly a year later Canvas became just the 10th product to achieve certification for criterion g(10) of the 2015 Cures Update. As a Care Modeling and Delivery Platform, the exchange of data between Canvas and our customers’ applications is pivotal. Our FHIR API is the crux of that data exchange, and while we currently support a broad range of workflows, we’re just getting started.
When we began work on our FHIR API, we saw it as just one of many methods of interoperability that would be equally supported. We weren’t sure who would be the main external data source, so we couldn’t focus on any particular standard. HL7, CCDA, flat files, FHIR, we wanted to be ready for it all. Soon after we realized that the single biggest producer and consumer of data stored within Canvas would be our own customers. Our typical customer is, like us, a healthcare technology company. Also like us, they prefer working with JSON structures and RESTful APIs over pipe-delimited TCP streams or verbose XML documents. Our customers are already using HTTP APIs to integrate with components of their tech stack (Stripe, Twilio, etc.), so it just makes sense for them to interact with their EHR in the same manner. Centering our FHIR API as the main point of integration was the correct decision. We implemented it as a facade sitting in front of a customer’s EHR server container, translating between FHIR and our internal data models. Viewing it as a simple (ha!) data transformation, we opted to implement the facade via an industry standard integration engine that provides a FHIR extension that allows it to act as a web server. This had the side benefit of automatically handling some of the more arcane details of the standard, and allowed us to focus on the mappings between FHIR and Canvas’ internal models.
This worked, and continues to work today. It has served hundreds of millions of our customers’ FHIR requests, but not painlessly. Implementing the API inside an integration engine meant structuring our transformation code according to the preferences of an integration engine. To a team of experienced python developers, this was painful. I have no doubts this approach is suitable for smaller scale operations that only require a small number of FHIR resources to be supported. If you’re already familiar with the integration engine, this can be a quick way to get started. We quickly realized that the integration engine made several aspects of development difficult. It disincentivized code sharing across multiple developers’ parallel efforts, comprehensive testing was difficult, getting meaningful error messages back to the client was cumbersome, and adjusting the concurrency at runtime was, well, not impossible, but it wasn’t a fun time. We encountered noisy neighbor problems resulting in request queuing. What should have been fast, simple requests were stuck waiting on much larger requests to finish. On top of that, every step in the transformation included writing out to the integration engine’s transactional database. We mitigated these issues to the extent reasonable, then began work on the next iteration. I thank the existing API for getting us where we are today, and to serving our customers as best it could, but we understand the problem we’re solving much better now, and it’s time to move on.
Enter the second iteration of the Canvas FHIR API. Based on FastAPI, v2 is highly concurrent, stateless, and much easier to develop, test, and deploy. v2 has instrumented metrics collection, and we now surface our response times in a public dashboard. We use pydantic with FHIR resource definitions and custom validation methods to produce error messages that are much friendlier to developers.
Creating a patient without a birthdate (required field)
Canvas FHIR API v1:
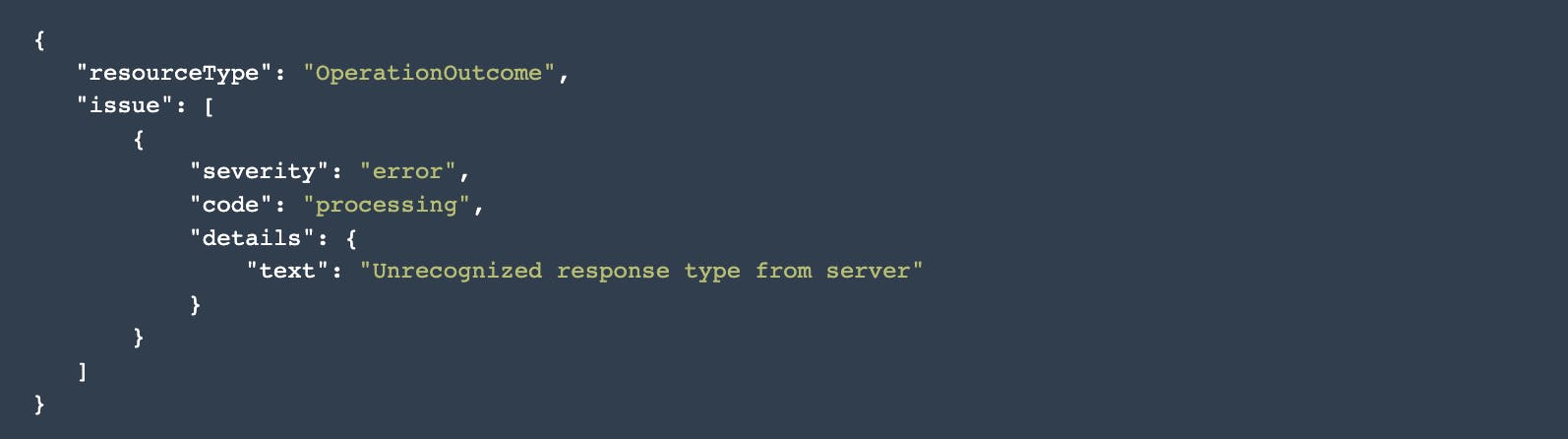
Canvas FHIR API v2:
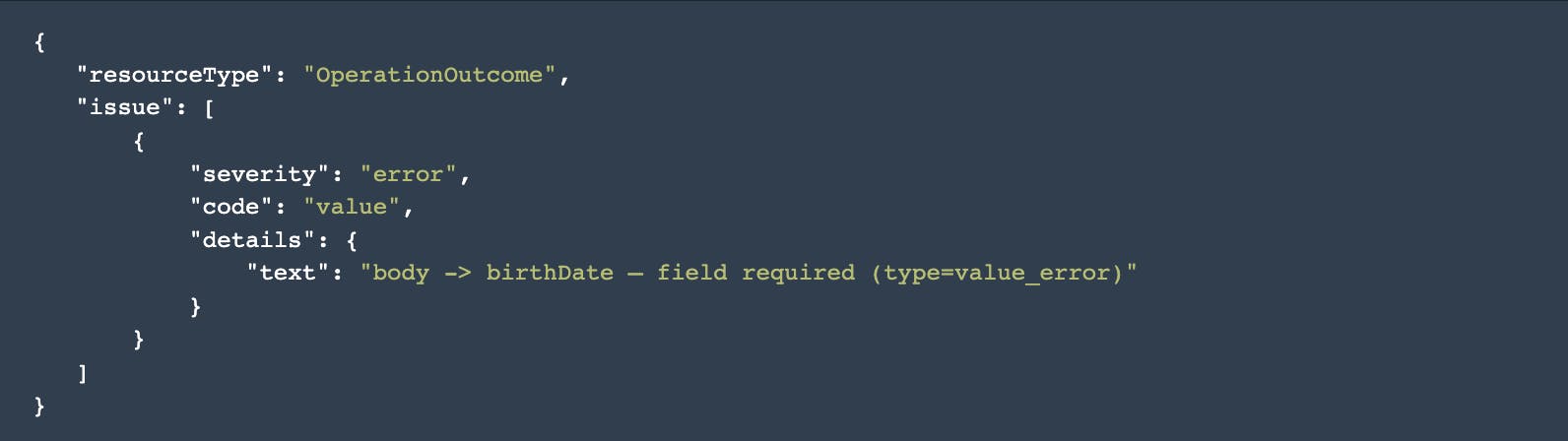
Our current API took us over a year to develop, the rewrite took months to achieve parity. We have unit tests, integration tests, and a much cleaner codebase. As a result, our roster of available contributors has grown significantly. More developers have access to contribute towards feature development and maintenance. This directly translates to better reliability and richer functionality for you. To ensure as smooth a transition as possible, we built a tool to replay API requests in v2 and search for behavioral differences. Those differences were reviewed and either fixed (if in error) or explained (if the change is desired). We went through this process for each FHIR resource we support before marking it as ready for use.
While we’re currently focused on ensuring a smooth transition for all existing customers, here’s where we’re headed next:
- Adding write capabilities to all endpoints that represent USCDI data elements
- Expanding permissioning logic to support patient-reported data workflows
- Increasing support for managing relationships between resources
- Adding configuration to enable customers to support safe access by their third-parties
- Improving our documentation by making it easier to see example responses
We’re excited to share these improvements with everyone. If you’re a current Canvas customer eager to try out the Canvas FHIR API v2, ask our support team to enable your access. Don’t worry, we won’t remove access to the API you’re currently using. If you’re not currently a Canvas customer, request a sandbox instance by contacting us.
